![[レポート] 目的に応じたマネージドデータベースの使い方が学べるワークショップ「Build a web-scale application with purpose-built databases & analytics [REPEAT]」 #DAT403-R1 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] 目的に応じたマネージドデータベースの使い方が学べるワークショップ「Build a web-scale application with purpose-built databases & analytics [REPEAT]」 #DAT403-R1 #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
AWS re:Invent 2024 で workshop 「Build a web-scale application with purpose-built databases & analytics [REPEAT](目的別データベースと分析機能を備えたウェブスケールのアプリケーションを構築する)」に参加しました。
[REPEAT] がついているのは re:Invent 期間中何回か開催されるセッションで、過去の re:Invent でも開催された可能性があるものです。
このワークショップでは、AWS から提供されている様々なデータベースを目的に応じて使い分けながらウェブアプリケーションを構築する手法を学ぶことができました。
概要
タイトル:DAT403-R1 | Build a web-scale application with purpose-built databases & analytics [REPEAT]
このワークショップでは、目的別データベースを使用して、スケーラブルな最新のウェブアプリケーションを構築する方法を学びます。Amazon Aurora、Amazon DynamoDB、Amazon ElastiCache、Amazon Neptune、Amazon OpenSearch Service を使用して開発パターンを適用し、完全な機能と拡張性を備えた書店向けeコマースアプリケーションを構築する方法を学び、その過程でベストプラクティスを深く掘り下げていきます。AWS Identity and Access Management (IAM)、Amazon VPC、ネットワーク、ストレージサービスなどのAWSの概念とサービスについて基本的な知識があることが推奨されます。参加するには、ノートパソコンを持参する必要があります。
スピーカー
Taylor Riggan(Principal Graph Architect, Amazon Neptune, Amazon Web Services)
Arjan Schaaf(Senior DynamoDB Specialist Solutions Architect, Amazon Web Services)
Thursday, December 5
12:30 PM - 2:30 PM PST
Mandalay Bay | Lower Level North | Islander I
Session types: Workshop
Topic: Analytics, Databases
Area of interest: SaaS
Level: 400 – Expert
Role: Developer / Engineer, IT Professional / Technical Manager, Solution / Systems Architect
Services: Amazon Aurora, Amazon DynamoDB, Amazon Neptune
ワークショップ資料
サンプルとして利用した book store アプリのコードは以下で公開されています。
あとから気づいたのですが、以下でワークショップは公開されていました。
レポート

スピーカーとして登録されていたのは 2 名でしたが、会場には SA さんがたくさんいらっしゃって手厚くサポートが受けられる状態でした。

AWS から提供されているマネージドなデータベースサービスはたくさんあります。一つの汎用的なデータベースをすべてのアプリケーションで使うのではなく、アプリケーションの使い方にマッチする一番適したデータベースを選択して使い分けるのが最もパフォーマンス良くコストも最適にすることができます。
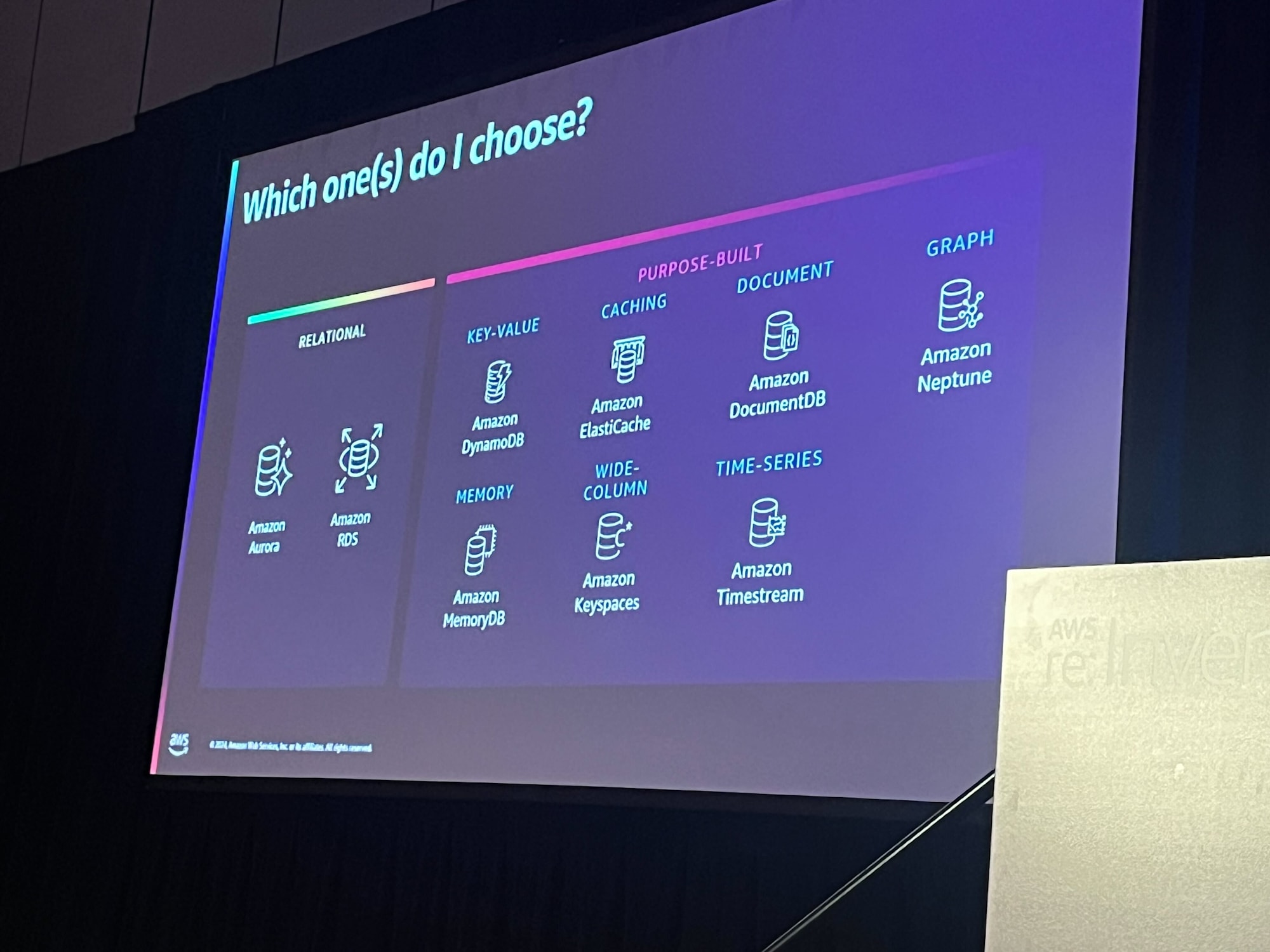
本ワークショップではサンプルとしてブックストアアプリを使用します。このブックストアアプリは本の購入以外にもカタログ一覧の表示や検索、おすすめ、ランキングなど様々な機能があります。これらの機能に特化したデータベースを使ってブックストアアプリの構築を進めていきます。
最初に正常なブックストアアプリを使って機能の確認をした後、データベースの連携が壊れたサイトを修正していくという流れです。

構成
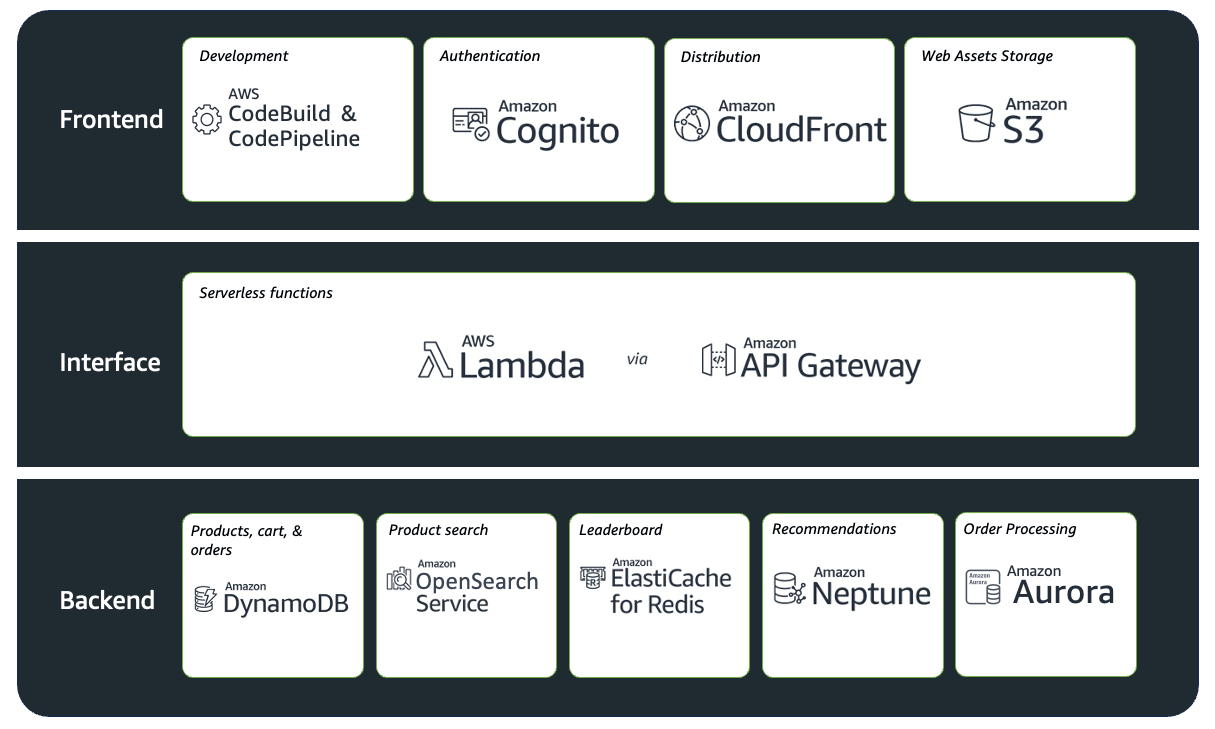
ブックストアアプリに使われている AWS サービスのイメージはこちらです。(ワークショップサイトから引用)
CI/CD は CodePipeline で行われていて、フロントエンドは CloudFront で配信をしています。インターフェイスは Lambda と API Gateway を使っていて、バックエンドに様々なデータベースが使われています。
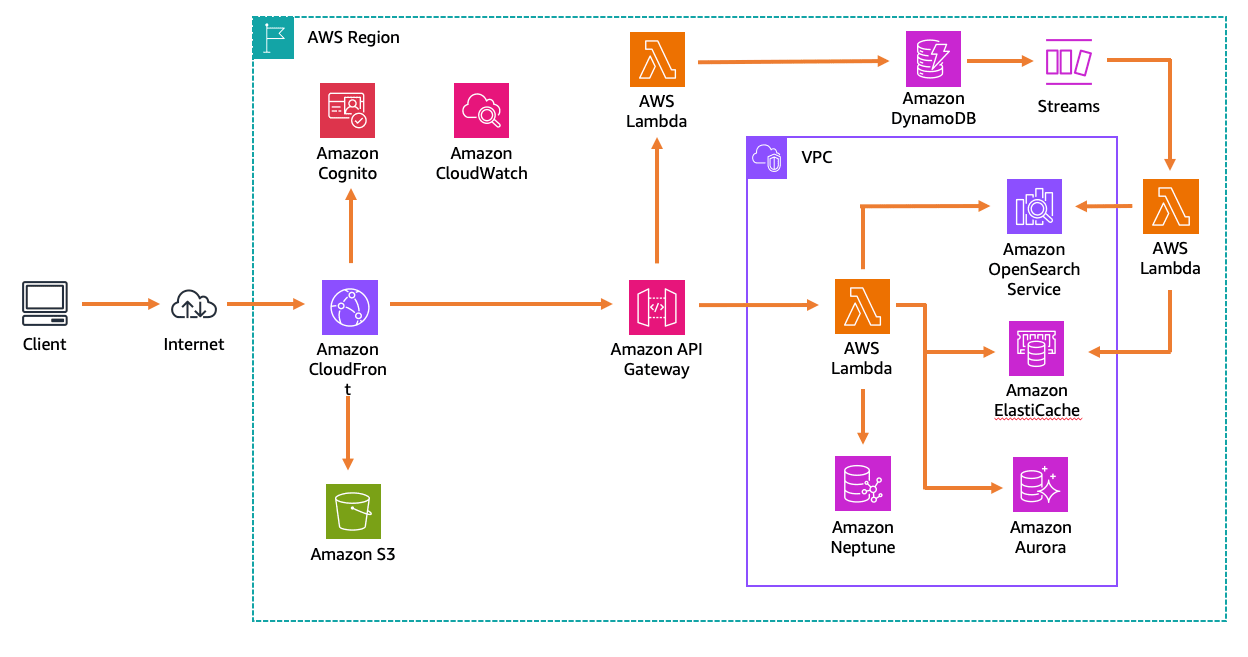
データベースへの登録やデータ取得は Lambda 関数を駆使します。
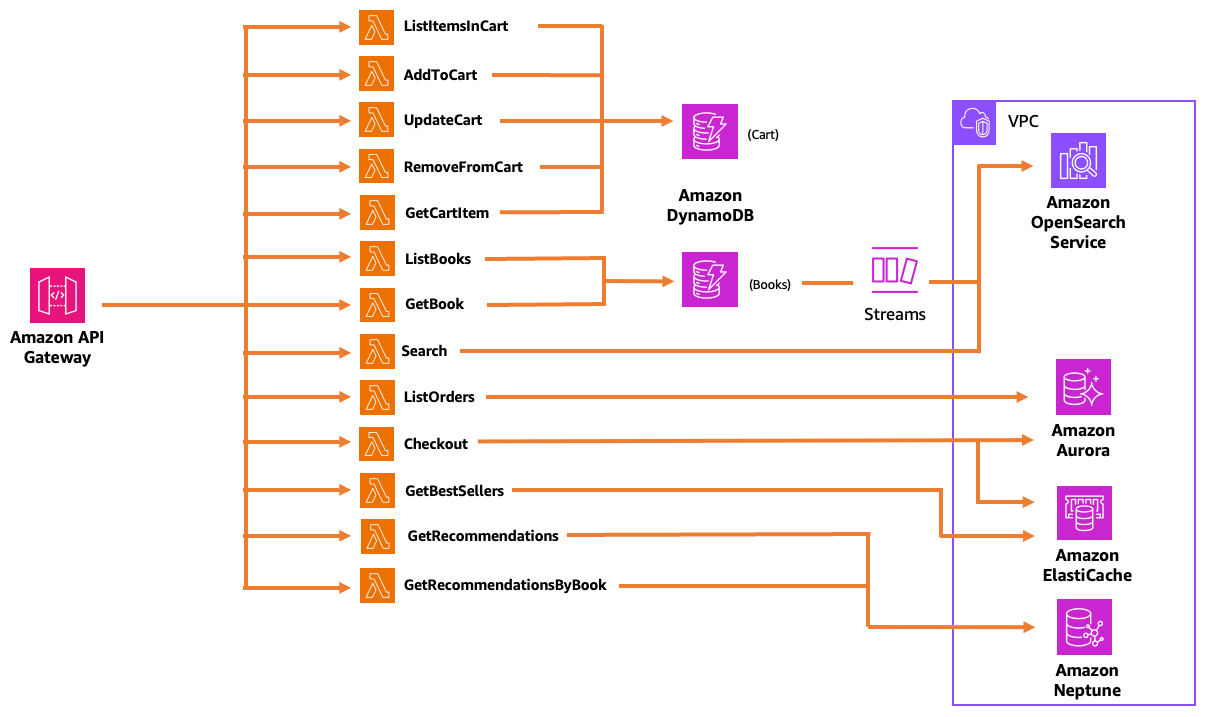
それぞれのデータベースは以下の用途で使われています。
- キー/バリューストア (Amazon DynamoDB) によって駆動されるショッピングカート
- メモリ内のソートセット (Amazon Elasticache Redis) によって駆動されるベストセラーリスト
- リレーショナルデータベース (Amazon Aurora PostgreSQL) による注文処理
- ドキュメント検索インデックスストア (Amazon OpenSearch) によって駆動される製品検索
- キー/バリューストア (Amazon DynamoDB) によって駆動される製品カタログ
- グラフデータベース (Amazon Neptune) によるレコメンデーション
ブラウザの開発者ツールで、ホームページにリストされている書籍がバックエンドの製品カタログからどのように取得されるかを確認できます。私は Google Chrome を使っているので、以下のスクショのようになります。

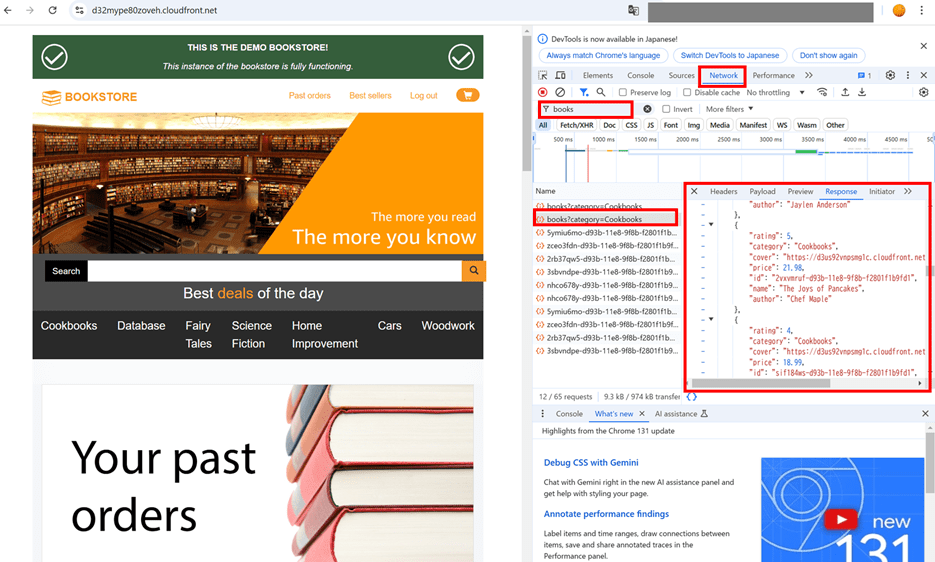
DynamoDB
まずは本のカタログが保存されている DynamoDB で、本の一覧がどんな風に格納されているか確認します。
最初は GetBook API が壊れているのでエラーになります。
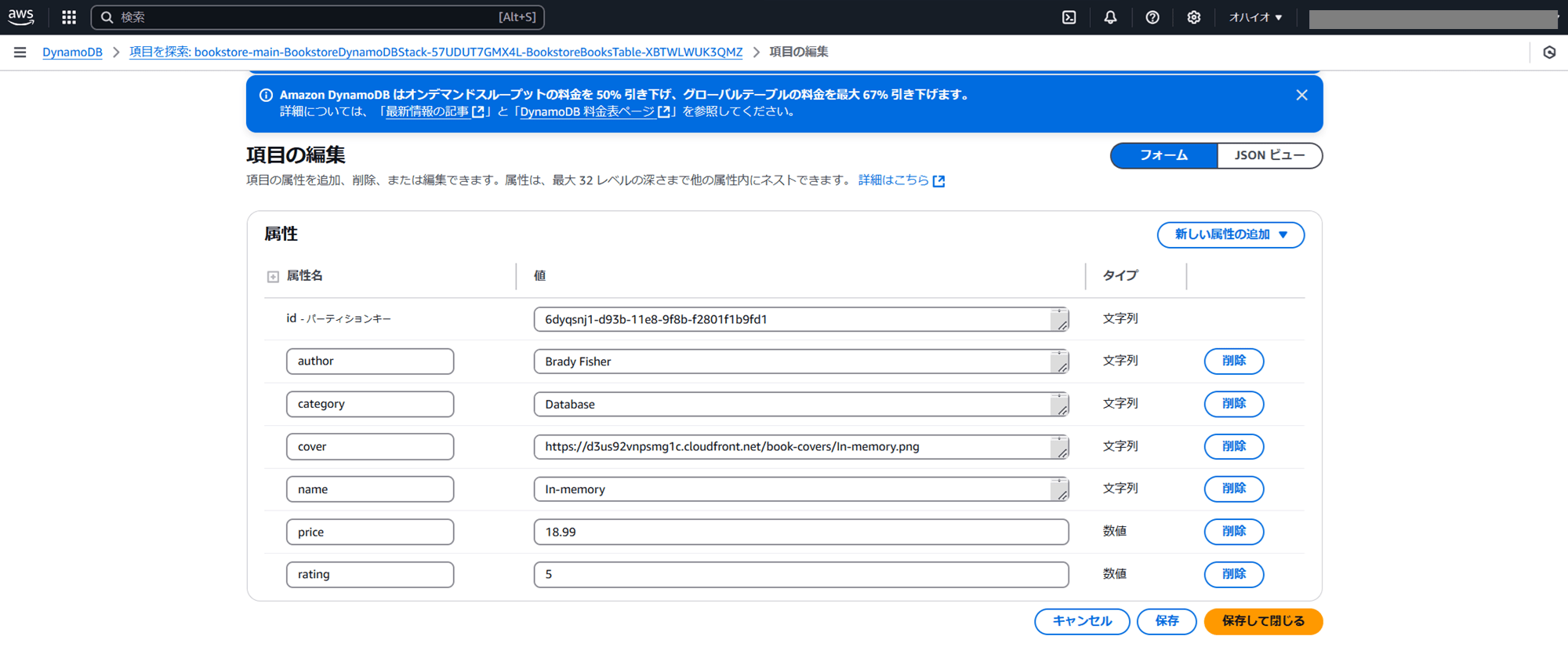
DynamoDB コンソールから、格納されているアイテムを確認できます。以下のように、1 冊の本に対して著者、カテゴリ、カバー、書籍の名前などのデータが含まれています。
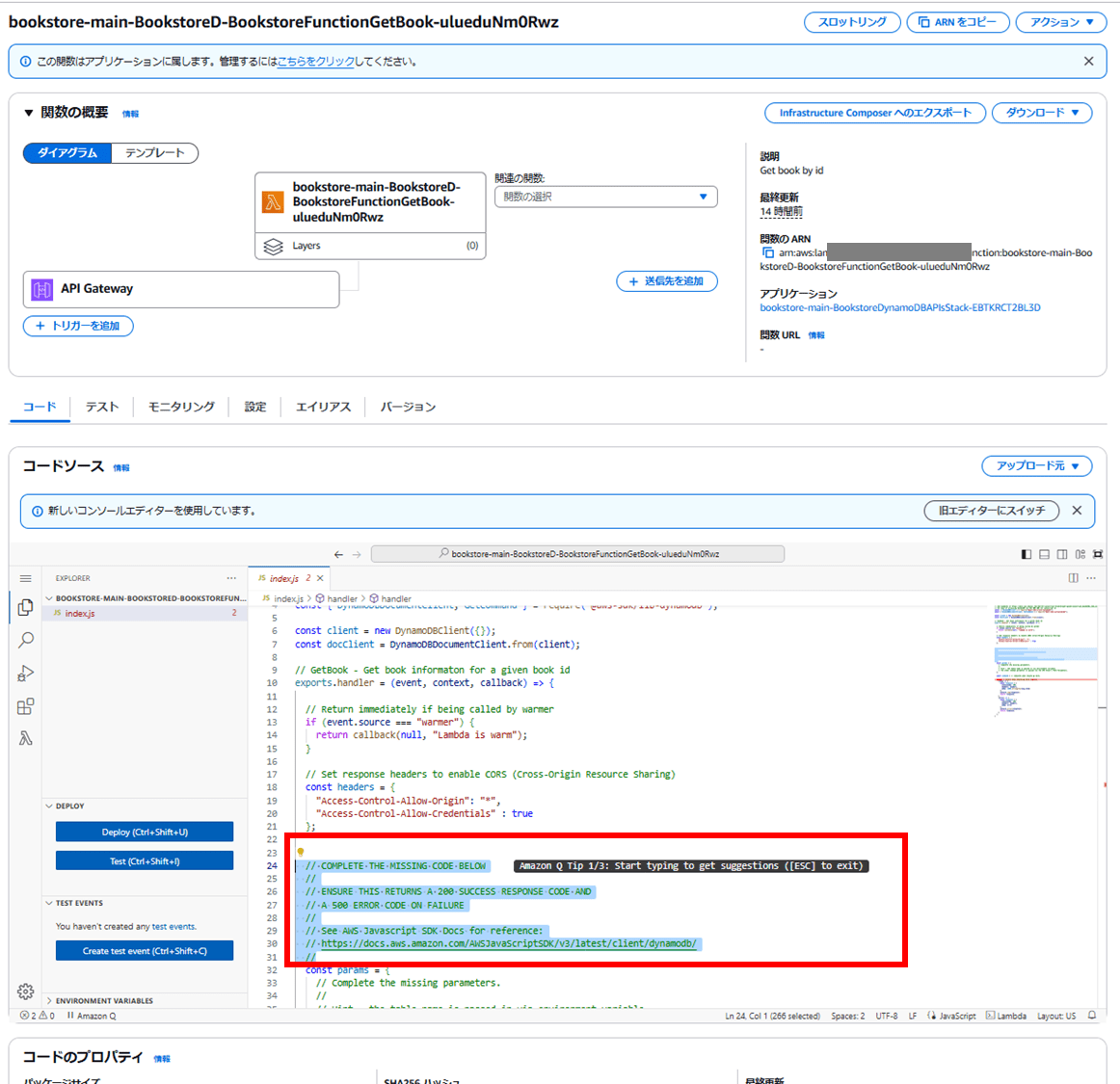
書籍の情報を取得する Lambda 関数のコードを修正します。
修正したLambda 関数をテストします。
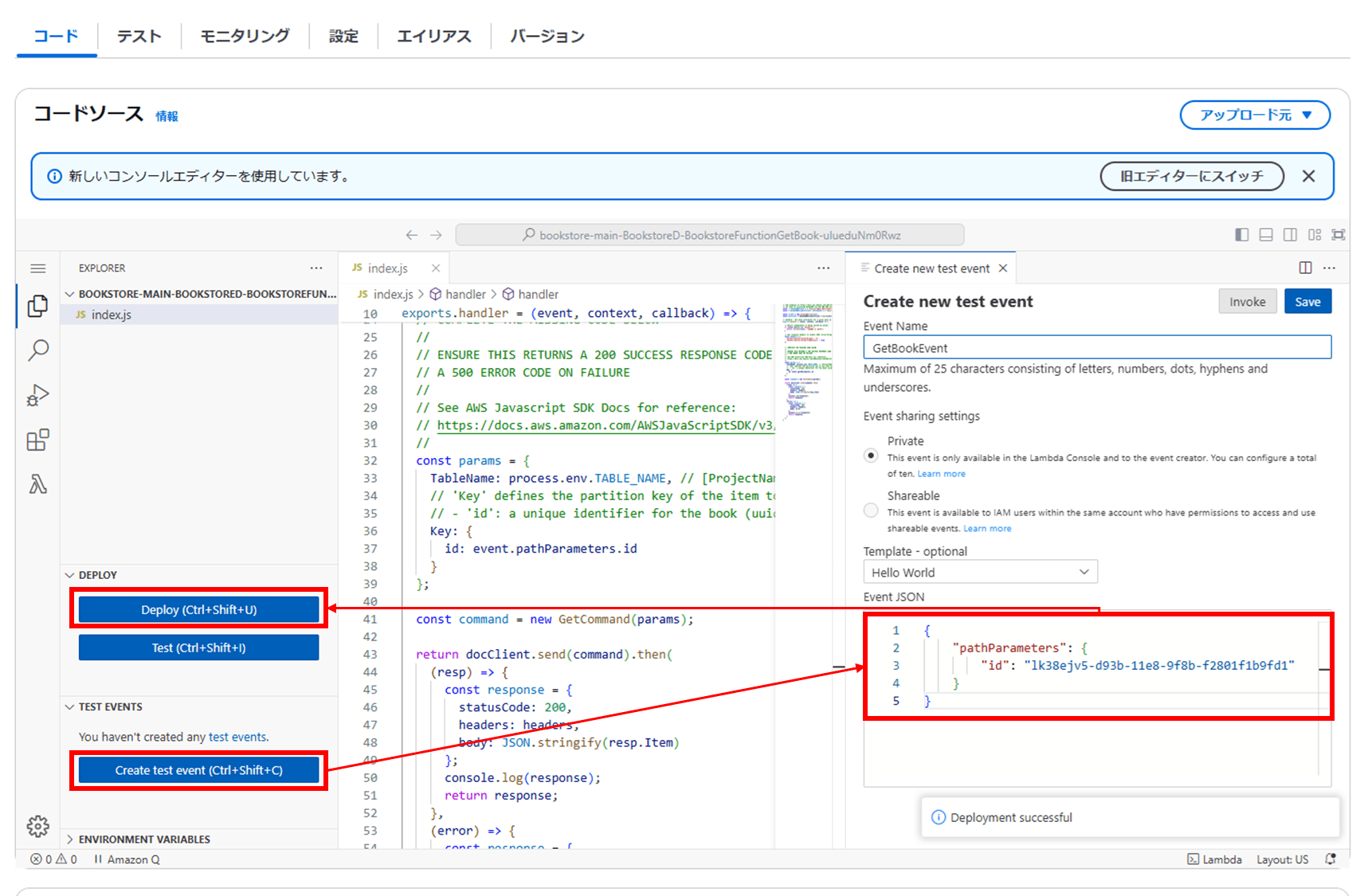
修正が完了すると、エラーにならずブックストアアプリのトップページが表示されるようになります。
Neptune
続いて Neptune を使います。
EC サイトを使っていると「この商品を買った人は、こんな商品も買っています」というおすすめ表示を見かけることがあると思います。このおすすめの仕組みは主に「協調フィルタリング」という手法が使われています。簡単に言うと「似た興味を持つ人が買った商品を見つけ出す」という方法です。
例えば「プログラミング入門」という本を検索して表示しているとすると、システムは「この本を買った人は他にどんな本を買ったのか」を調べ、関連する本をおすすめとして表示します。
さらに最近では SNS の友達関係も活用する傾向があります。友達同士は似た興味を持っていることが多いため、友達が購入した商品も良いおすすめになるかもしれません。
このように、「誰が何を買ったか」という購入履歴と「誰が誰と友達か」という SNS での関係性を組み合わせることで、より良い商品のおすすめができるようになります。
本ブックストアアプリでは、この関係性を効率的に管理するために、グラフデータベースという特殊なデータベース…つまり Neptune を使用しています。
多くのグラフデータベースユーザーは、グラフデータのモデリング、グラフクエリの作成、グラフクエリ結果の視覚化を行う際に、Jupyter ノートブックを活用しています。Neptune コンソールから Jupyter ノートブックを開くことができます。

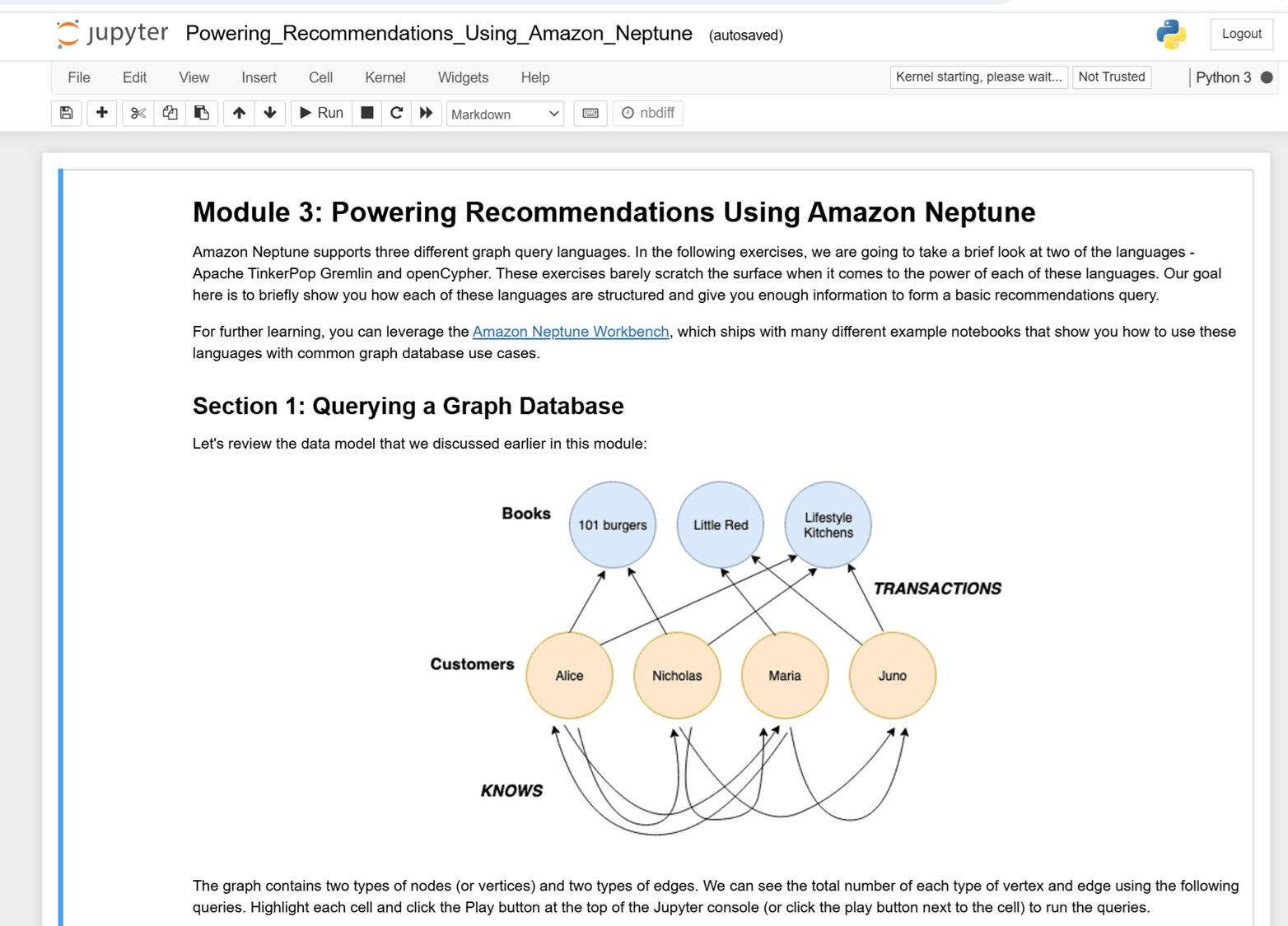
Jupyter ノートブックを閉じて、先ほどと同様に GetRecommendations API を実装するために Lambda コンソールを開きます。
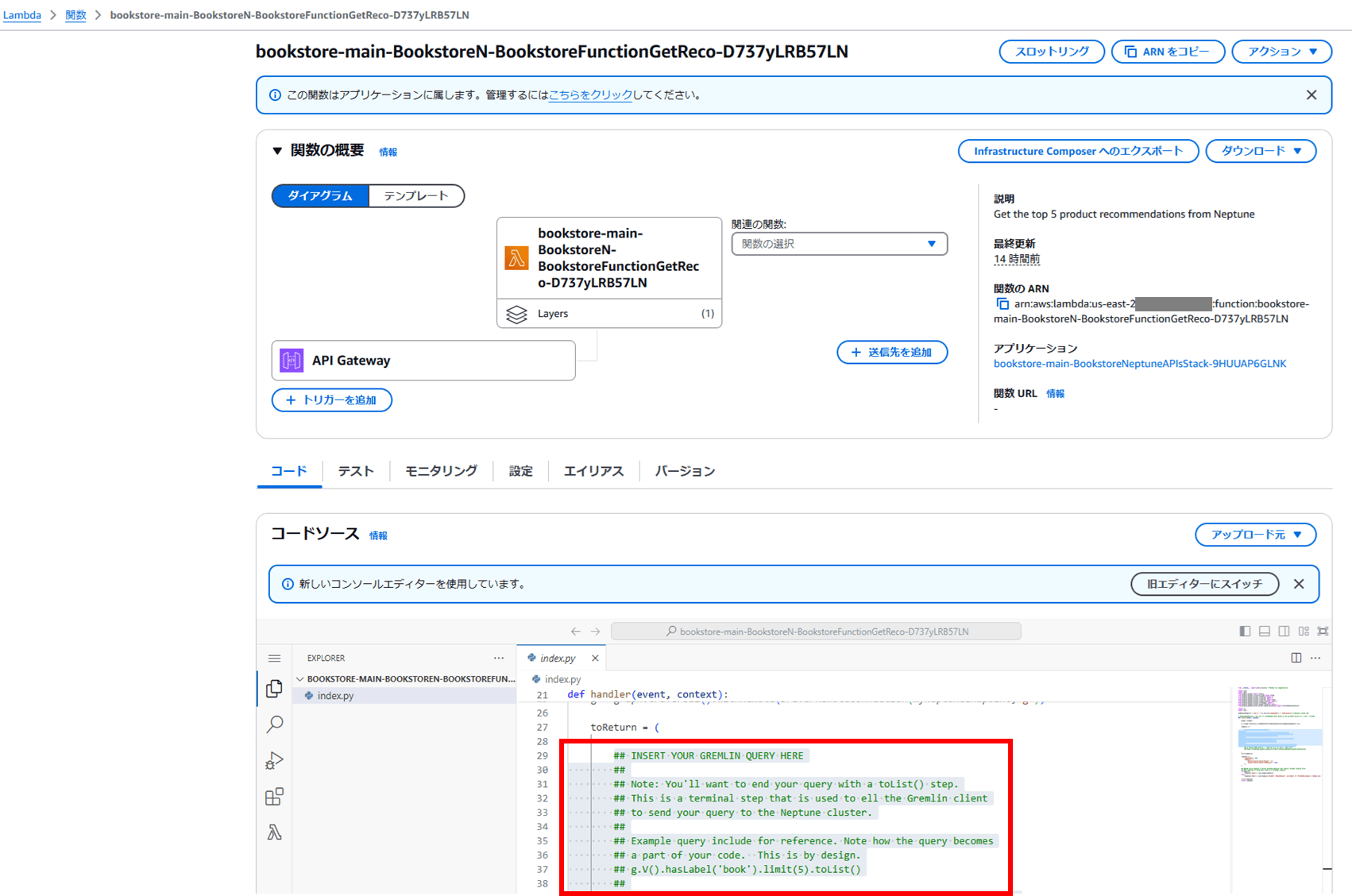
修正が完了すると、「Books your friends have bought」というセクションにおすすめの本が表示されるようになります。
ElastiCache
ブックストアのベストセラーランキングは多くのユーザーが頻繁に見る機能です。しかし、このランキングデータを通常のデータベースで管理すると、アクセスが集中した時にシステムへの負荷が高くなってしまいます。
そこで ElastiCache for Redis を使います。Redis には「Sorted Set(ソート済みセット)」という機能があり、売上数に応じて自動的に順位を更新できます。本が売れるたびにこのデータは更新され、常に最新のランキングが維持されます。
また、上位 20 件だけを取り出すような処理も Redis なら高速に実行できます。多くのユーザーが同時にアクセスしても、スムーズにランキングを表示できるというわけです。
ElastiCache は単なるキャッシュとしてだけでなく、ランキング機能を効率的に実現するためのデータベースとしても活用されています。
ベストセラーページは最初エラーになっています。
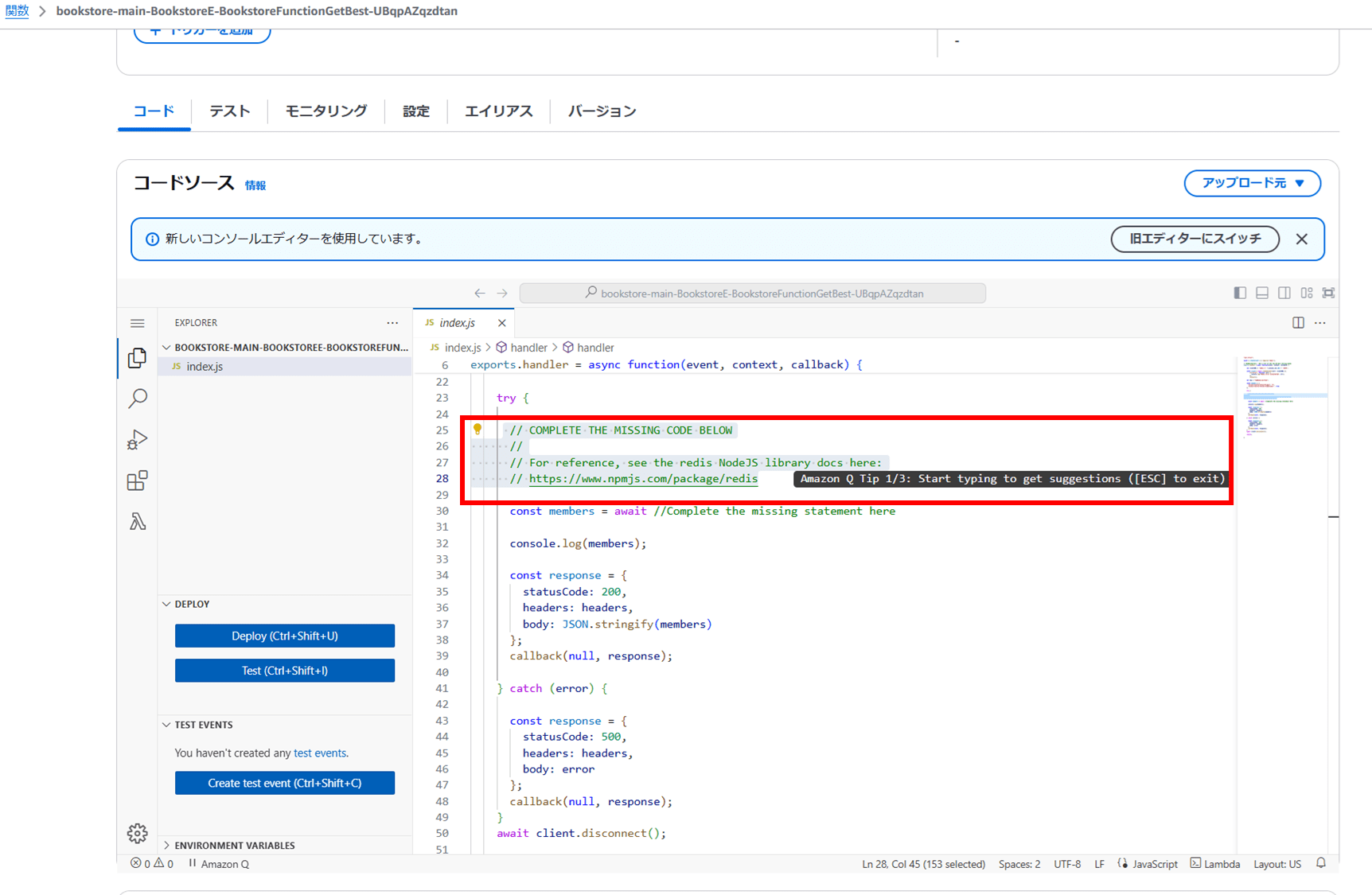
Lambda 関数を開き、GetBestSellers API を修正します。
コードが修正できたら、何か本を購入する操作をします。購入に基づいて、ベストセラーが表示されるようになります。
最近は Amazon ElastiCache for Valkey が登場したので、ひょっとしたらこちらを使っていくようになるのかもしれません。
OpenSearch
書籍の検索機能は OpenSearch Service で実現しています。
書籍データは DynamoDB で管理していますが、DynamoDB は検索が不得意です。例えば「Python」で検索した時に「入門Python」、「Pythonプログラミング」といった関連書籍を見つけることは困難です。
そこでブックストアアプリでは DynamoDB Streams を使用し、DynamoDB のデータが変更されると自動的に OpenSearch Service にもその内容がコピーされるようになっています。このような自動連携の仕組みを Zero-ETL 統合と呼びます。Zero-ETL 統合は OpenSerach Service コンソールの「パイプライン」で実装されています。
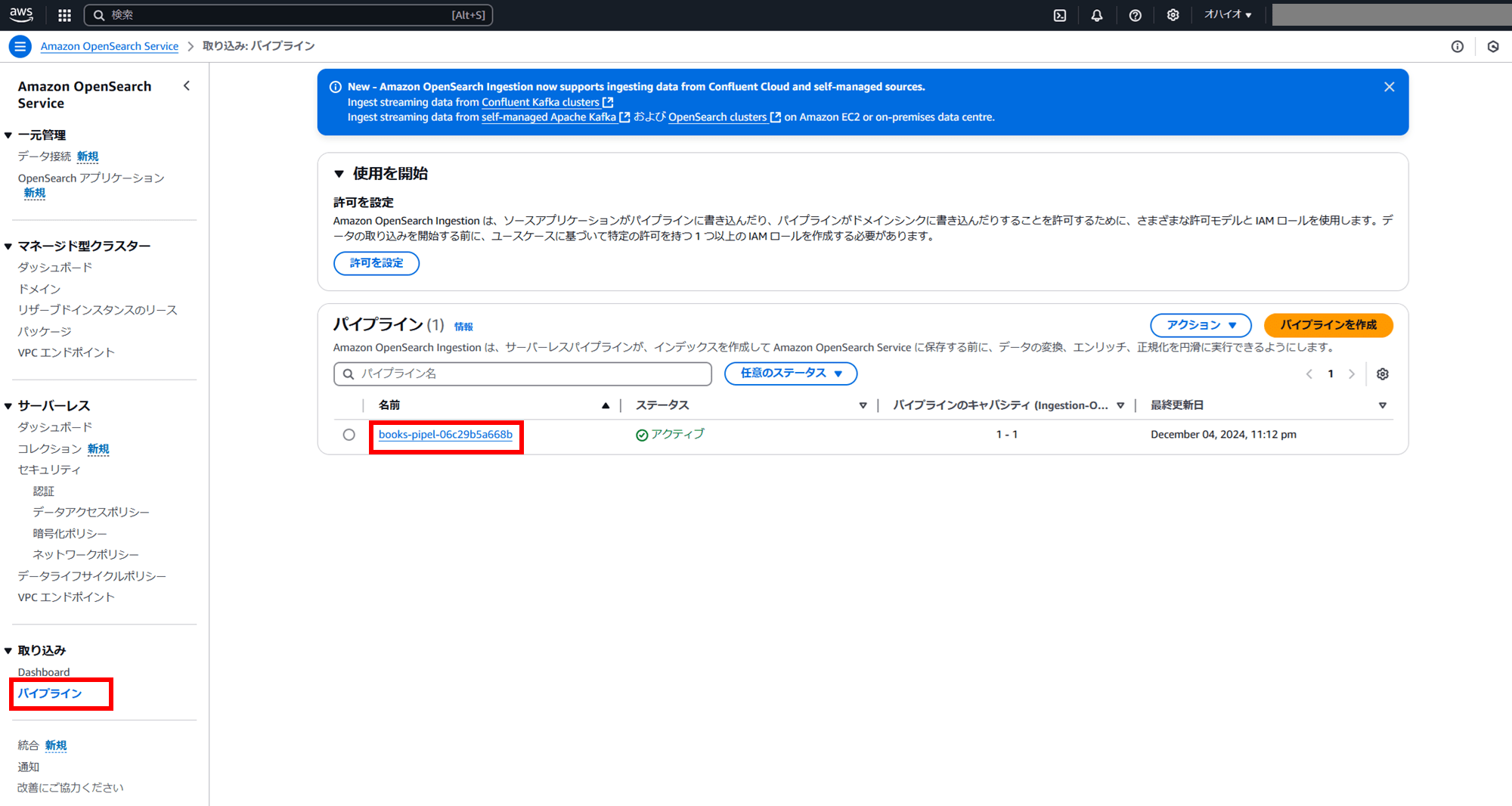
OpenSearch ではコピーされたデータに対して全文検索用のインデックスを作成します。これによりタイトルや著者名、カテゴリーなどから、より柔軟な検索が可能になります。ユーザーは部分一致での検索や、関連度の高い順での検索結果の表示といった機能を利用できます。
さて、最初は Search API が壊れているのでエラーになっています。
Lambda コンソールから Search API のコードを修正します。
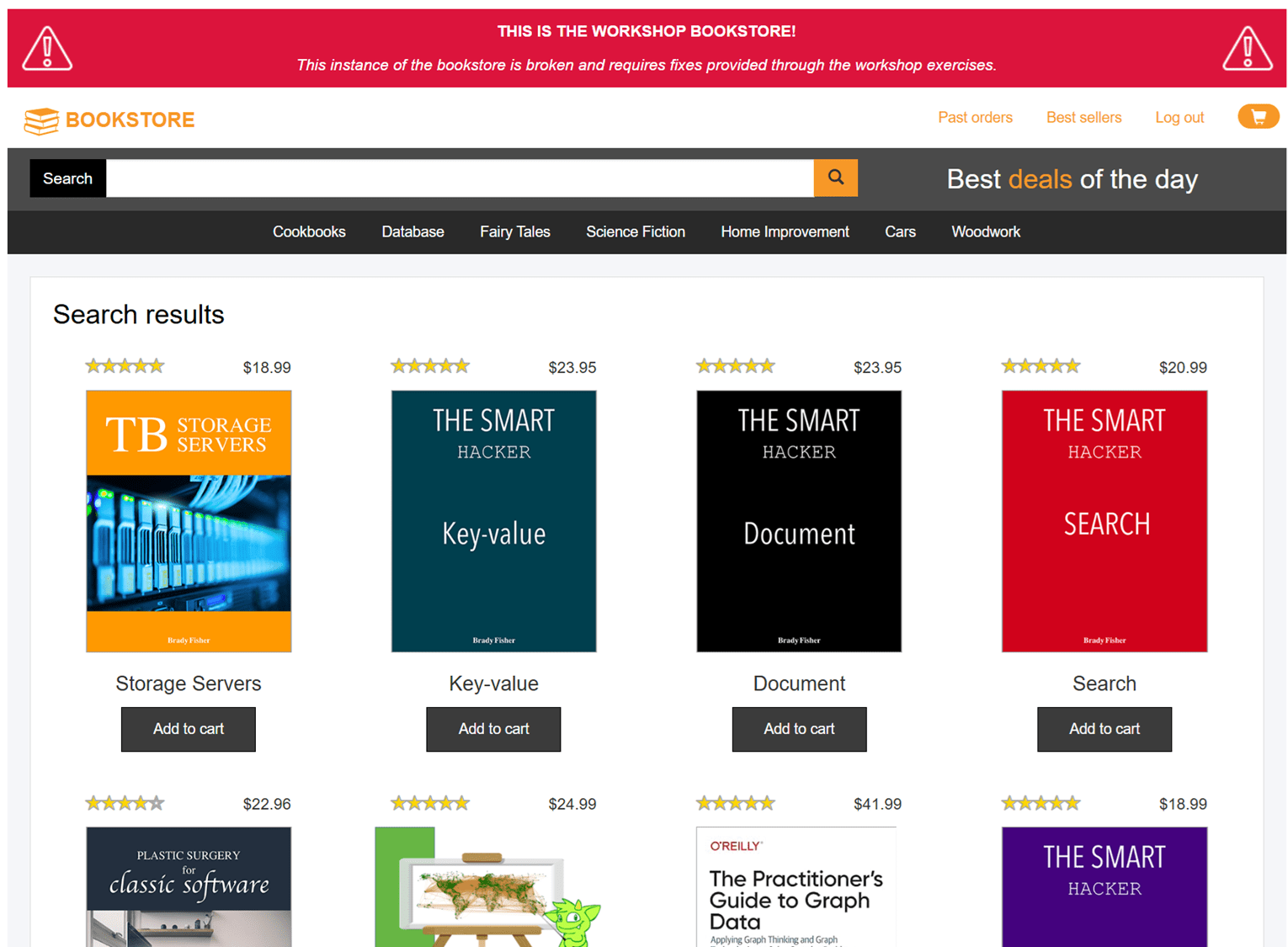
コードを修正すると、検索できるようになりました。
Aurora
さて、過去の注文処理は Aurora PostgreSQL で管理されています。
Aurora クラスターがあり、注文データが格納されています。
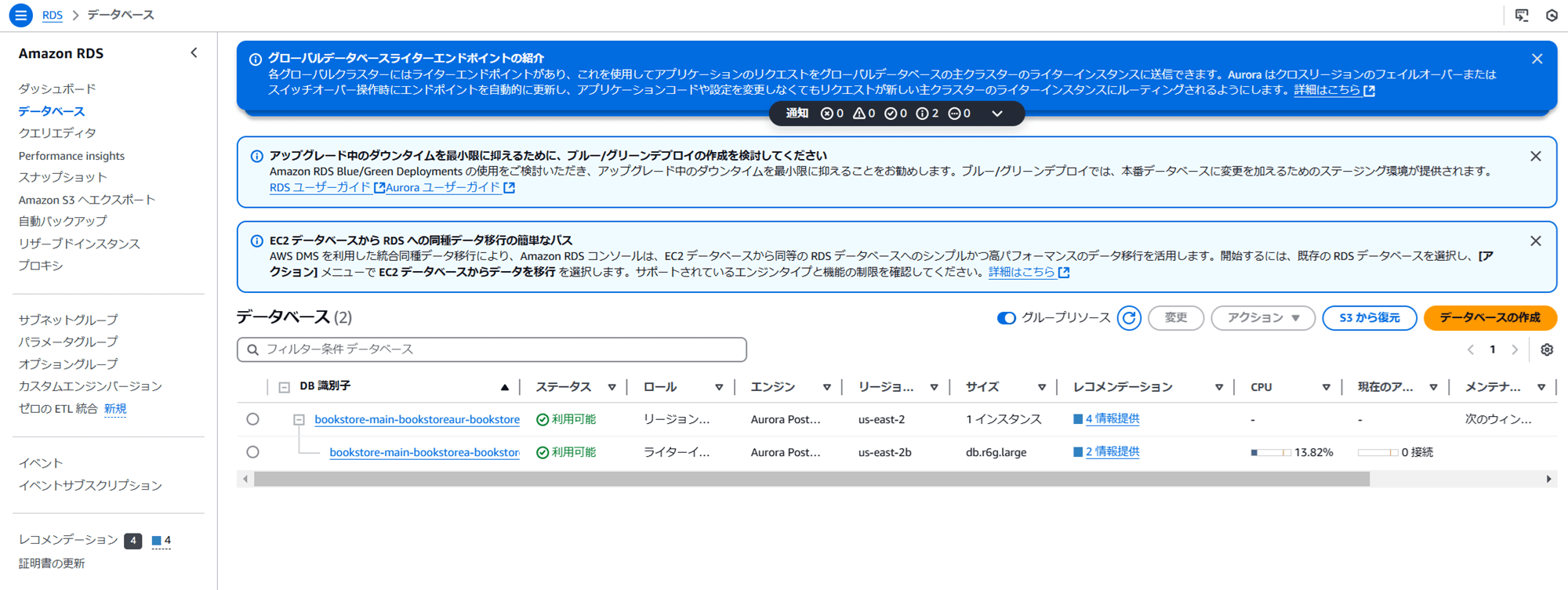
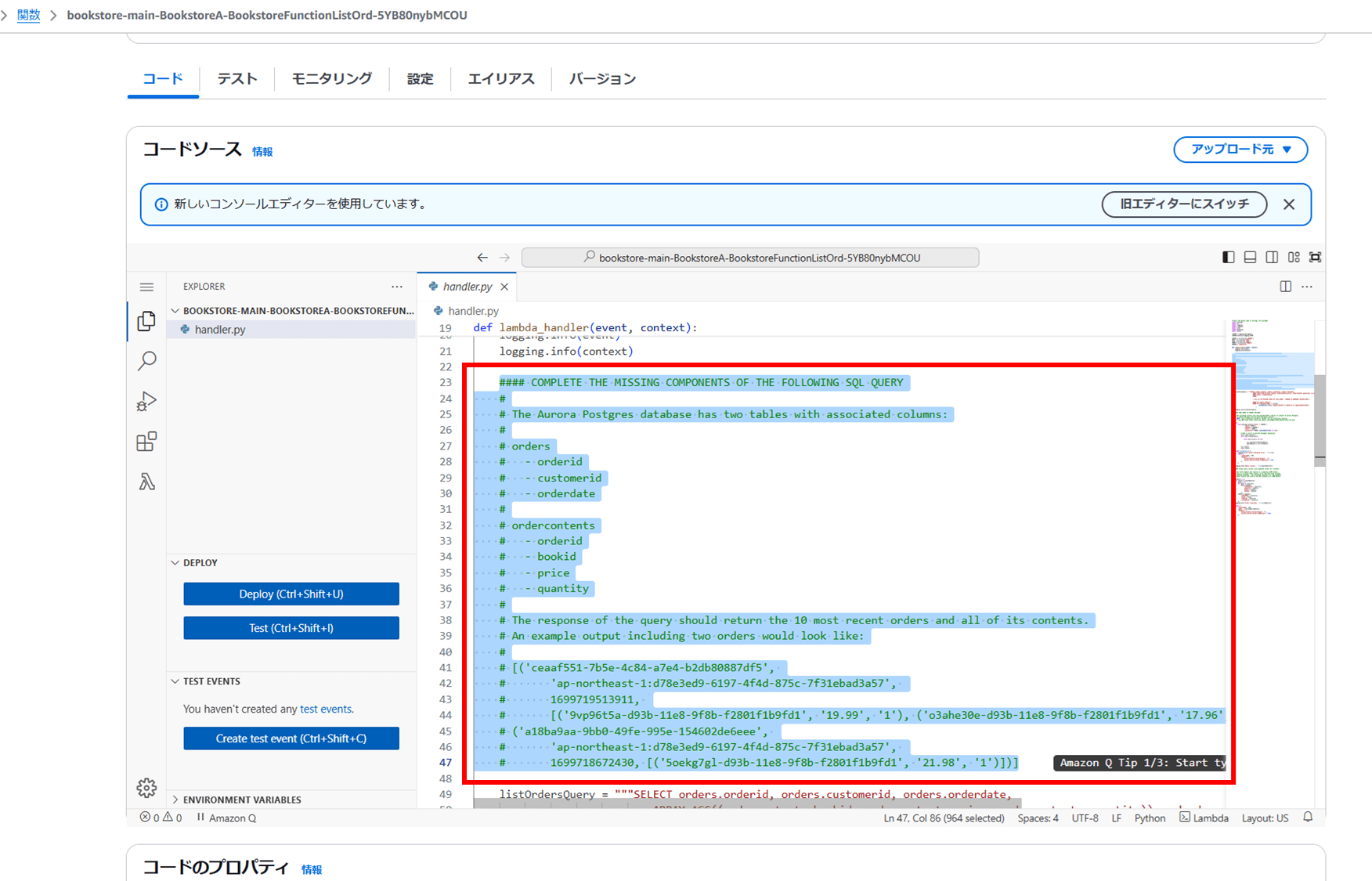
Lambda コンソールから ListOrders API を修正します。
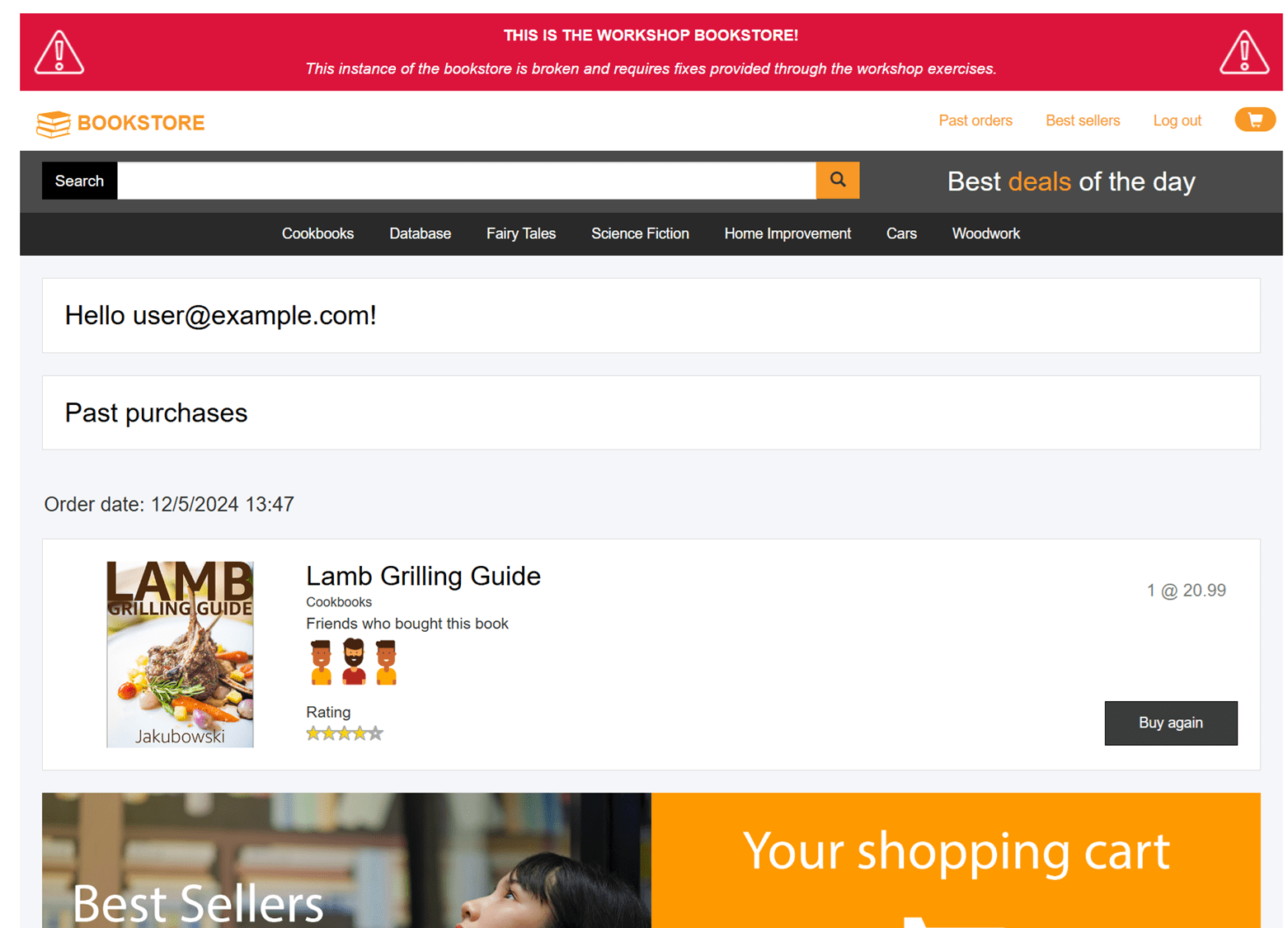
コードを修正すると、注文履歴が確認できるようになりました。
QuickSight への連携と可視化
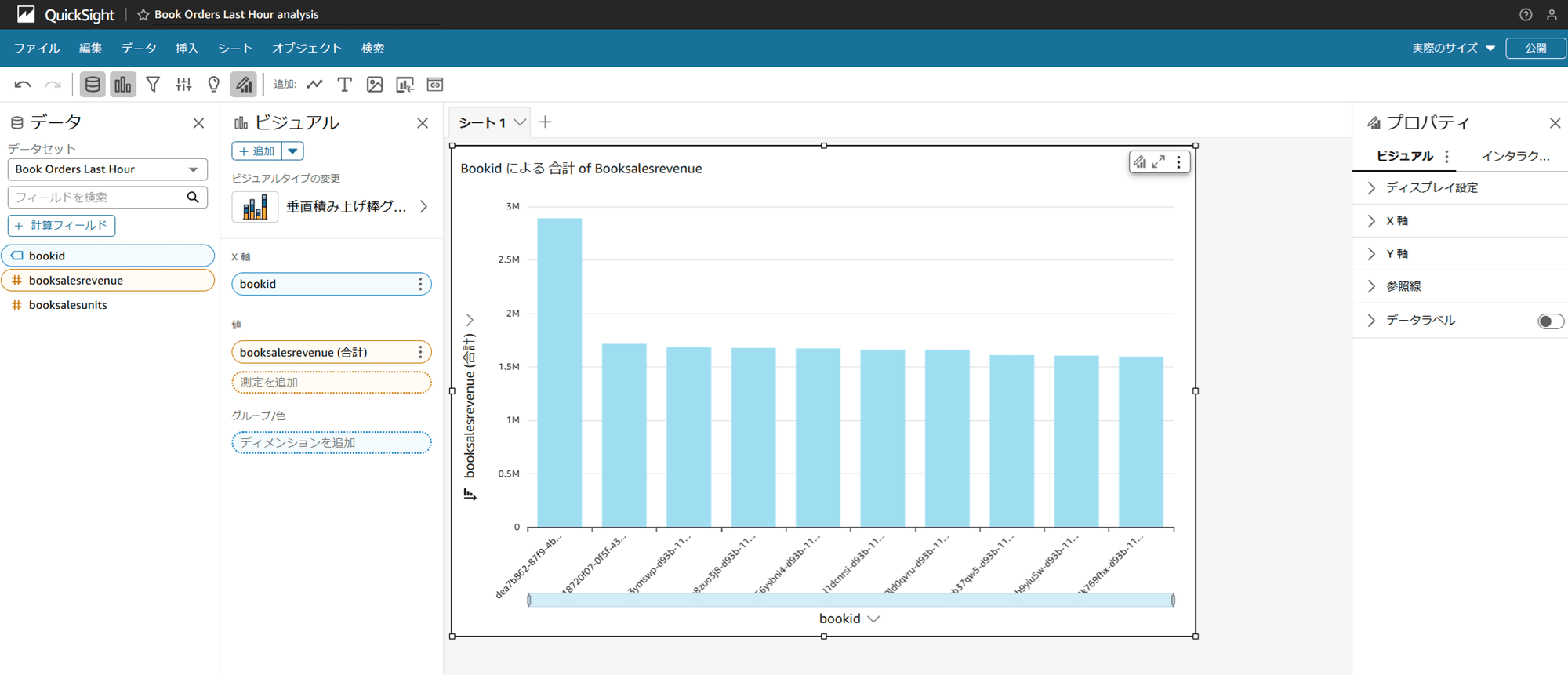
最後に、ブックストアアプリの Aurora クラスターを直接クエリするように QuickSight を設定して注文を可視化します。
QuickSight アカウントを有効化します。
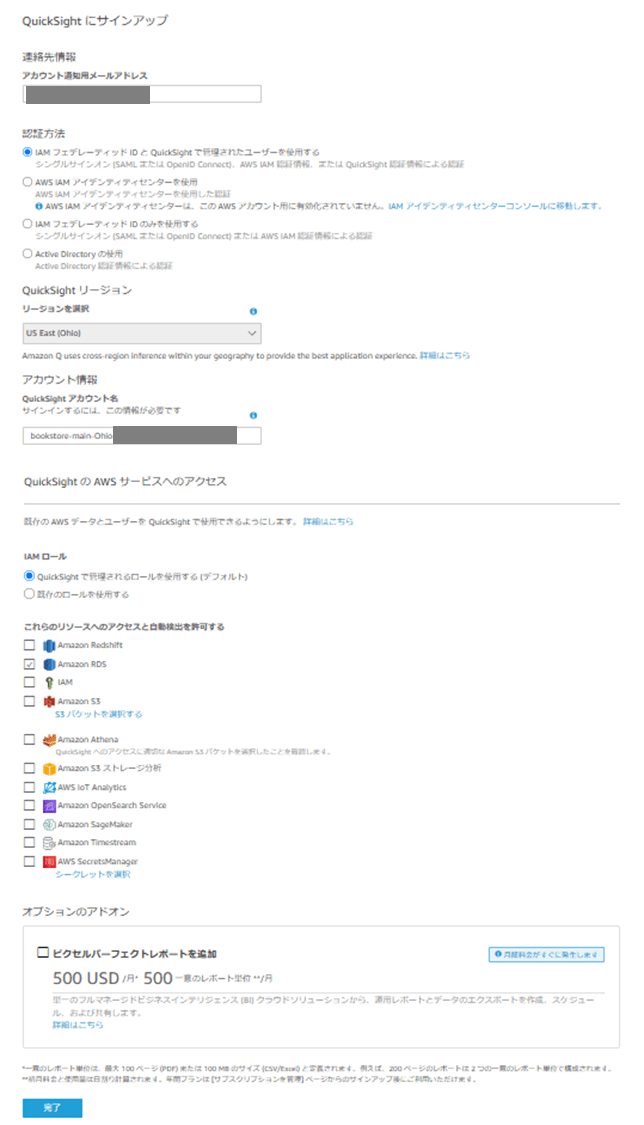
Aurora は VPC の中にあるので、QuickSight が VPC 内のリソースにアクセスするために「VPC 接続」という設定を行う必要があります。
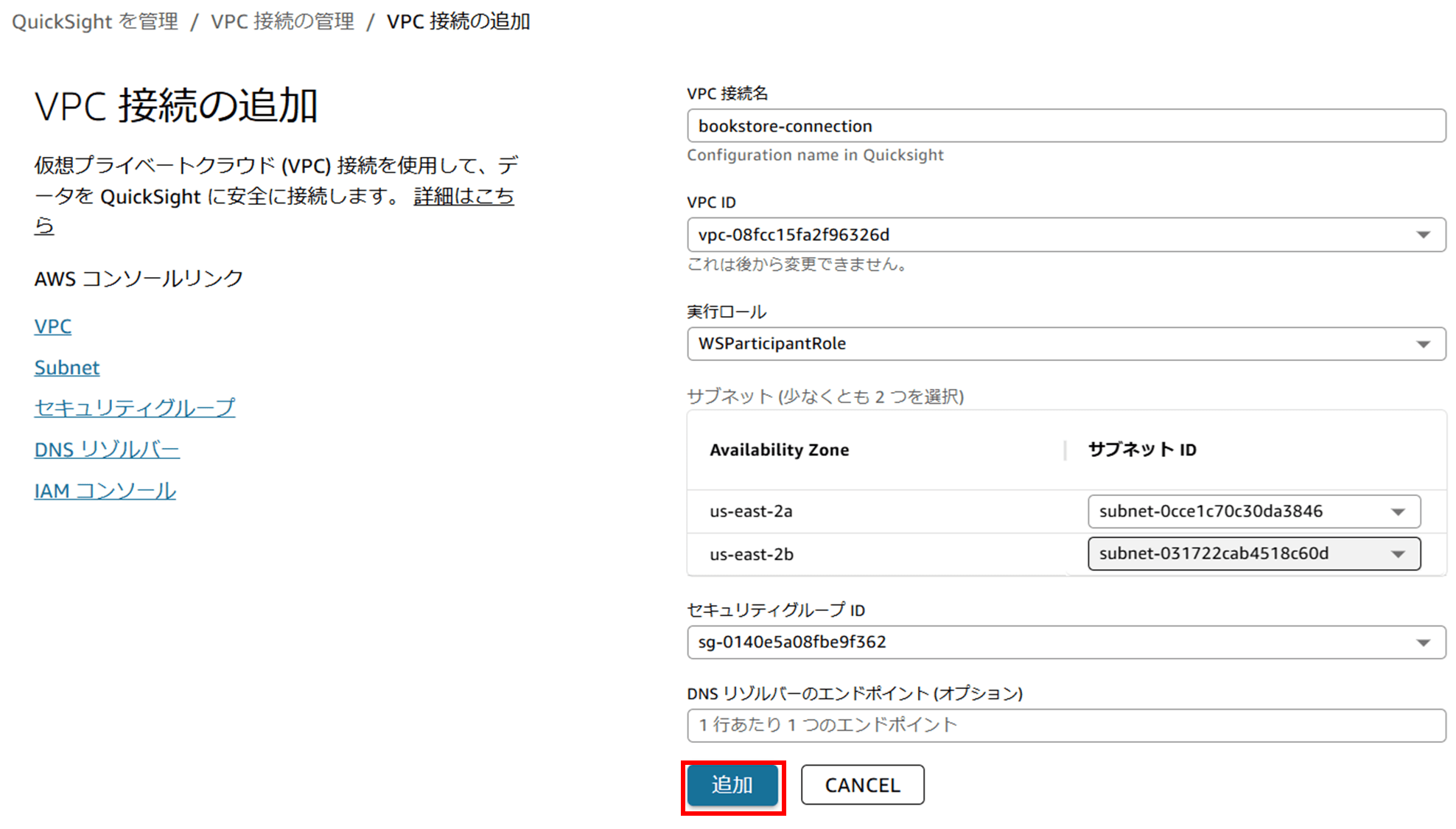
接続できると、QuickSight で注文を可視化できるようになりました。
終わりに
最近はデータベースについて勉強したいなと思っていたので、各データベースの目的や使い方が分かる、うってつけのワークショップでした。REPEAT セッションでしたが満足度が高かったです。
ちなみにこのセッションが私の re:Invent 2024 最後のセッションとなりました。ほぼすべての会場でセッションを受講しましたが、メイン会場から一番遠いマンダレイベイが私は一番好きでした。最後のセッションがマンダレイベイで良かったです。









